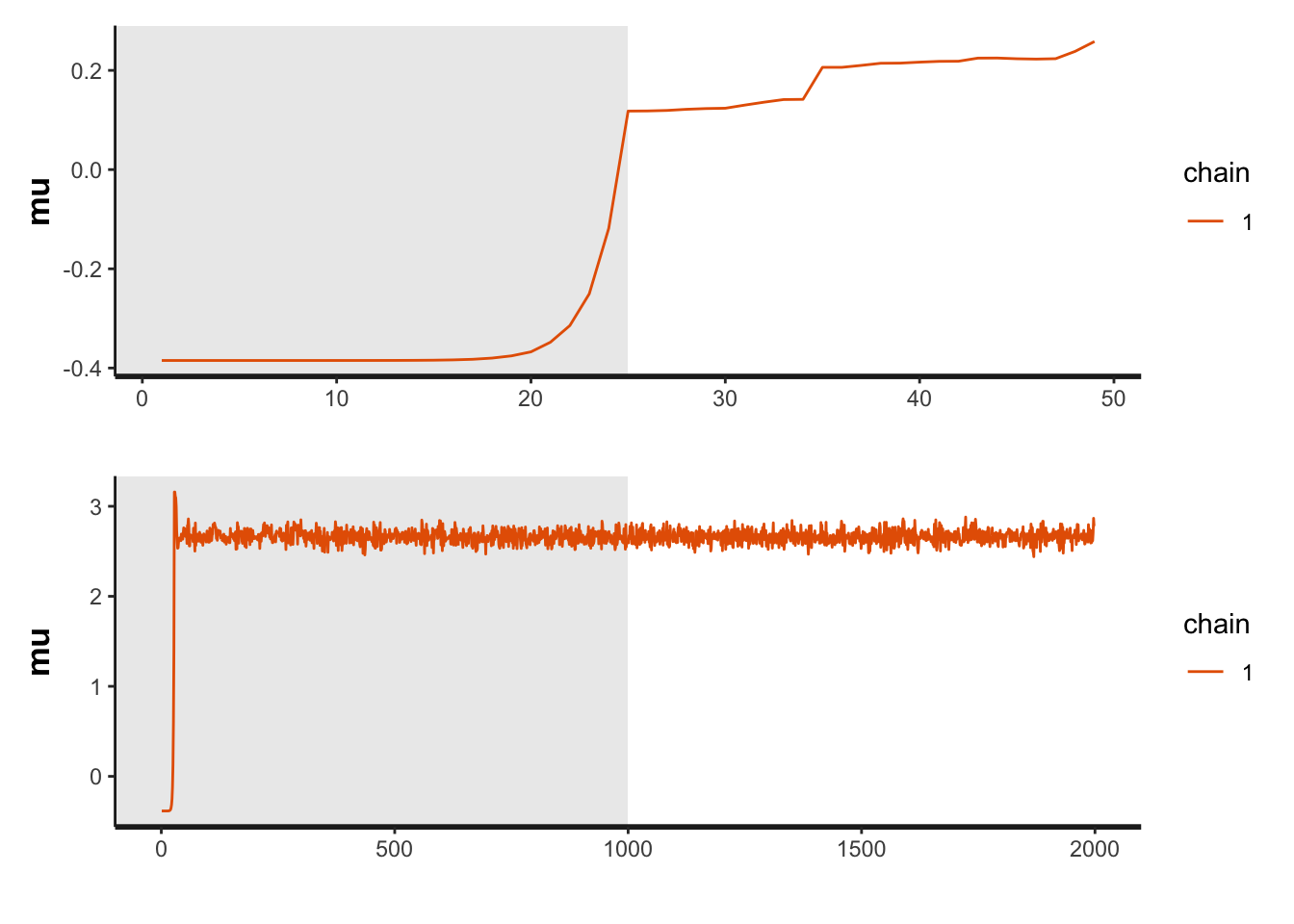
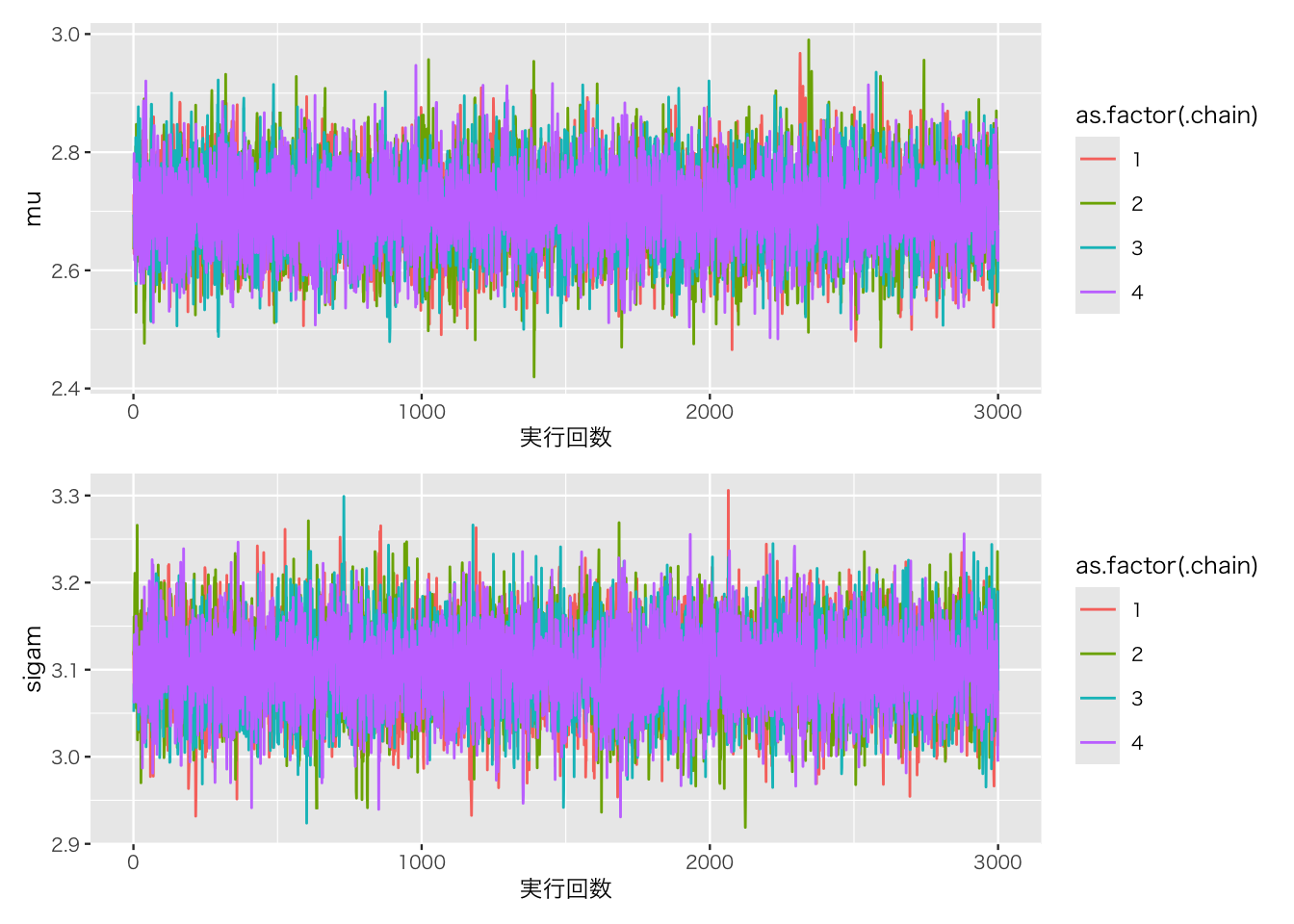
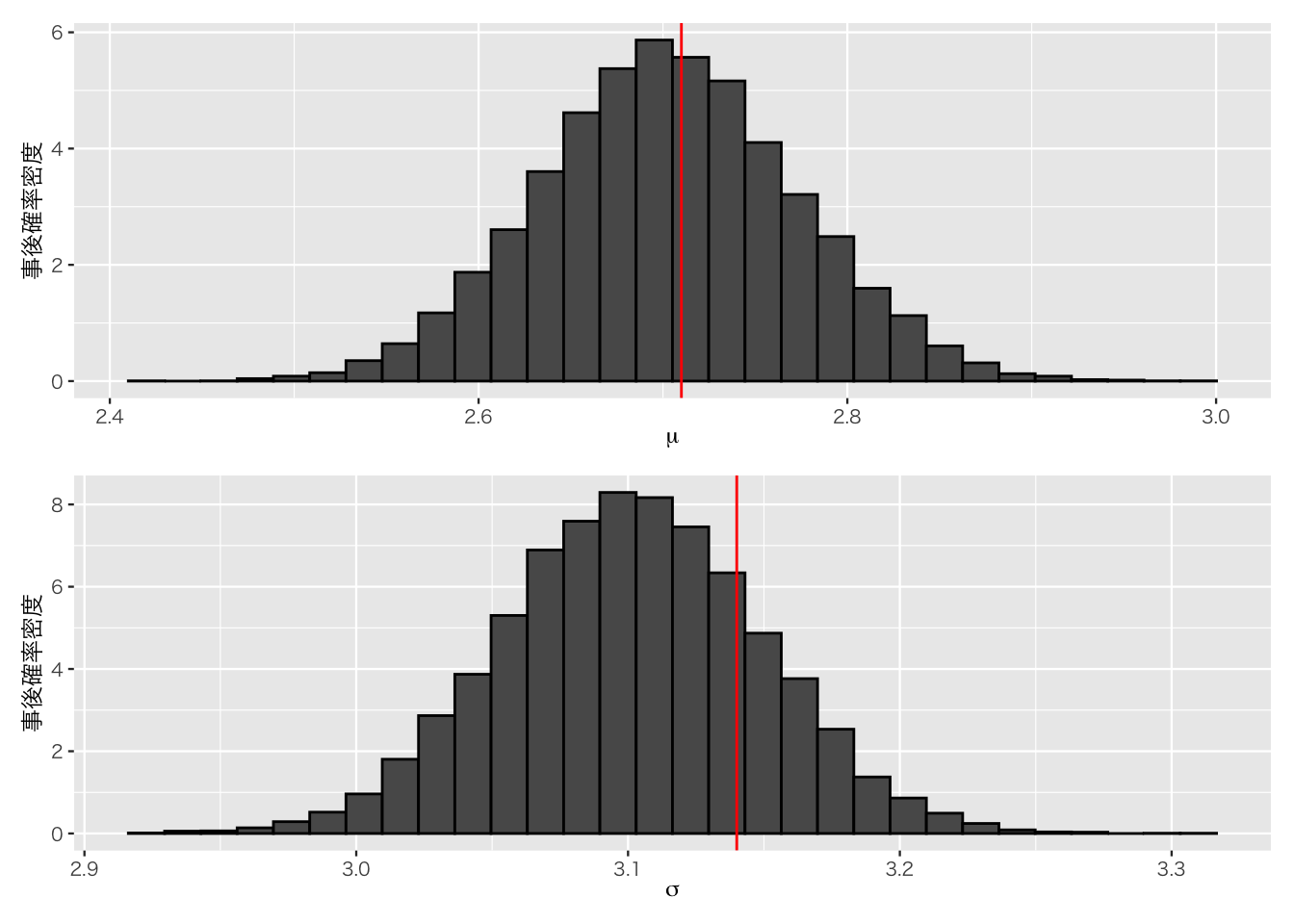
t <- 0.1 #初期のiPhoneのシェアを表す
a <- matrix(c(t, 1 - t,1-t,t), nrow = 2)
a [,1] [,2]
[1,] 0.1 0.9
[2,] 0.9 0.1p <- matrix(c(0.4, 0.9,0.6, 0.1), nrow = 2)
p #遷移核 [,1] [,2]
[1,] 0.4 0.6
[2,] 0.9 0.1p1 <- a%*%p
p1 #t=1 [,1] [,2]
[1,] 0.85 0.15
[2,] 0.45 0.55p2 <- p1%*%p
p2 #t=2 [,1] [,2]
[1,] 0.475 0.525
[2,] 0.675 0.325p3 <- p2%*%p
p3 #t=3 [,1] [,2]
[1,] 0.6625 0.3375
[2,] 0.5625 0.4375p4 <- p3%*%p
p4 #t=4 [,1] [,2]
[1,] 0.56875 0.43125
[2,] 0.61875 0.38125p5 <- p4%*%p
p5 #t=5 [,1] [,2]
[1,] 0.615625 0.384375
[2,] 0.590625 0.409375p6 <- p5%*%p
p6 #t=6 [,1] [,2]
[1,] 0.5921875 0.4078125
[2,] 0.6046875 0.3953125p7 <- p6%*%p
p7 #t=7 [,1] [,2]
[1,] 0.6039063 0.3960938
[2,] 0.5976563 0.4023438